


Quick Review:
So far, in this series about the history of Large Language Models (LLMs), we’ve covered three main periods:
The Early 1930s to late 1960s: The Rise and Fall of Mechanical Translation from which history started.
Bonus episode about AI winters 1966 to 1988: The Story of AI Winters and What it Teaches Us Today.
Introduction
Today, we immerse ourselves in the whirlpool of incredible proposals and developments that emerged in Artificial Intelligence (AI) and Machine Learning (ML) from 1990 to the mid-2000s. We explore how previous research, – despite the lack of computational power! – paved the way for modern Language Models (LLMs).
Luckily enough, since the decline of expert systems in the 1990s, there were no more AI winters. It truly became the renaissance of AI. During this time machine learning as we know it today was born. Though it’s impossible to cover everything that happened in ML and AI in an article, we will highlight the most significant events that have shaped the AI field and made the seemingly impossible possible. You might argue with what we chose! Please feel free to add your views to the comment section.
Before embarking on our journey, let’s describe what LLMs are. In a nutshell, LLMs are deep neural networks that utilize specialized architectures and undergo training on vast amounts of data. The first crucial keyword to consider is "neural networks*," which serves as an ideal entry point for our discussion. They didn’t “happen” in the 90s, so we will need to cover a bit of the 1960s – late 1980s. As our story unfolds, you will witness the progression of concepts, gradually growing more sophisticated, until we ultimately arrive at the era of LLMs.
*A neural network is a computational model inspired by the human brain, composed of interconnected artificial neurons that process and transmit information to learn and make predictions1960-1985: Progress and Setbacks of Neural Networks
The foundation for LLMs was laid long before the 1990s. In the 1940s, McCulloch and Walter Pitts pioneered artificial neural networks inspired by the human mind and biological neural networks. Marvin Minsky's SNARC system in the 1950s marked the first computerized artificial neural network.

SNARC - Teardown style
Although neural network research faced a decline in the late 1950s, a few dedicated researchers continued their work. In the 1960s, the discovery of multilayers opened new possibilities, leading to the development of feedforward neural networks* and backpropagation*.
*Feedforward neural network is a type of artificial neural network where information flows in one direction, from the input layer through the hidden layers to the output layer, without any loops or feedback connections.*Backpropagation is a training algorithm for neural networks that calculates and distributes error gradients through the network, allowing for efficient adjustment of the network's weights during the learning process
An image of the perceptron from Rosenblatt's “The Design of an Intelligent Automaton,” Summer 1958
In the 1960s, neural network research experienced both progress and setbacks. Frank Rosenblatt’s perceptron, an early type of artificial neural network, received considerable attention. It was designed to mimic the behavior of a single neuron, capable of learning and making simple decisions based on input data. Many believed that would help to solve complex problems. But soon, Marvin Minsky and Seymour Papert demonstrated the limitations of the perceptron in solving certain types of problems, which led to a disappointment and decline in funding for neural network research.

Frank Rosenblatt ’50, Ph.D. ‘56 works on the “perceptron” – what he described as the first machine “capable of having an original idea.”
Despite this setback, researchers persevered. A lot of progress was made around backpropagation. According to Encyclopaedia Britannica, the term back-propagating error correction was introduced by Frank Rosenblatt in 1962. But the real implementation was done by Paul Werbos, he described error backpropagation* in 1974. Its application to neural networks occurred in 1985 and was popularized by David Rumelhart, Geoffrey Hinton, and Ronald Williams in their influential paper titled "Learning representations by back-propagating errors" published in 1986. These and the availability of more computational power and large-scale datasets would later lead to the resurgence of neural networks in the 21st century, paving the way for the success of deep learning (a subfield of ML that focuses on training artificial neural networks with multiple layers) and models like LLMs.
*Error backpropagation is a method used in neural networks to adjust the weights of the connections between neurons by propagating the error from the output layer back to the input layer, allowing the network to learn and improve its predictions.Another important part of work was done with Convolutional Neural Networks* (CNNs). Kunihiko Fukushima's designs in 1979 introduced CNNs, such as Neocognitron, capable of recognizing visual patterns through hierarchical, multilayered architectures. Later, the combination of CNNs and backpropagation will have a significant impact on deep learning.

In 1979, Kunihiko Fukushima invented a multilayered artificial neural network called Neocognitron. It was the first Convolutional Neural Network (CNN) architecture.
*Convolutional neural networks are deep learning models specifically designed to process and analyze visual data, leveraging specialized convolutional layers for feature extraction and spatial hierarchies💔 The Separation of AI and Machine Learning
During the late 1970s and early 1980s, artificial intelligence and machine learning broke up (don’t worry, they will reunite later!). The separation was caused by different research focuses and methodologies: AI focused on symbolic reasoning while lacking learning capabilities, and ML became more specialized, focusing on statistical learning from data.
Late 1980s – Game-changing 1990s: The Development of Crucial Concepts and Methods
The 1990s brought a lot of changes. The machine learning industry, driven by neural networks, reorganized and flourished in that period. The exploration and discovery of new algorithms, approaches, and methods advanced with head-spinning speed. The ideas that were previously unattainable started to become a reality!
Let’s name a few very important developments:
Hidden Markov Model (HMM) gained significant attention in the 1980s and 1990s due to their successful application in speech recognition.
Statistical Language Models (SLMs) got a significant advancement. SLMs estimate the likelihood or probability of word strings and play a vital role in applications like automatic speech recognition, machine translation, and Asian language text input.
Increased computational power and the utilization of new ML algorithms, primarily focused on statistical models, gave push to Natural Language Processing (NLP). These laid the groundwork for later progress in areas like machine translation and question-answering systems.
Support Vector Machines (SVM) were developed by Vladimir Vapnik and colleagues in AT&T Bell Labs and became popular for classification tasks due to their ability to handle high-dimensional data and nonlinear decision boundaries. At that moment, neural networks were tiny, unstable, and unreliable and took a lot of time to train.
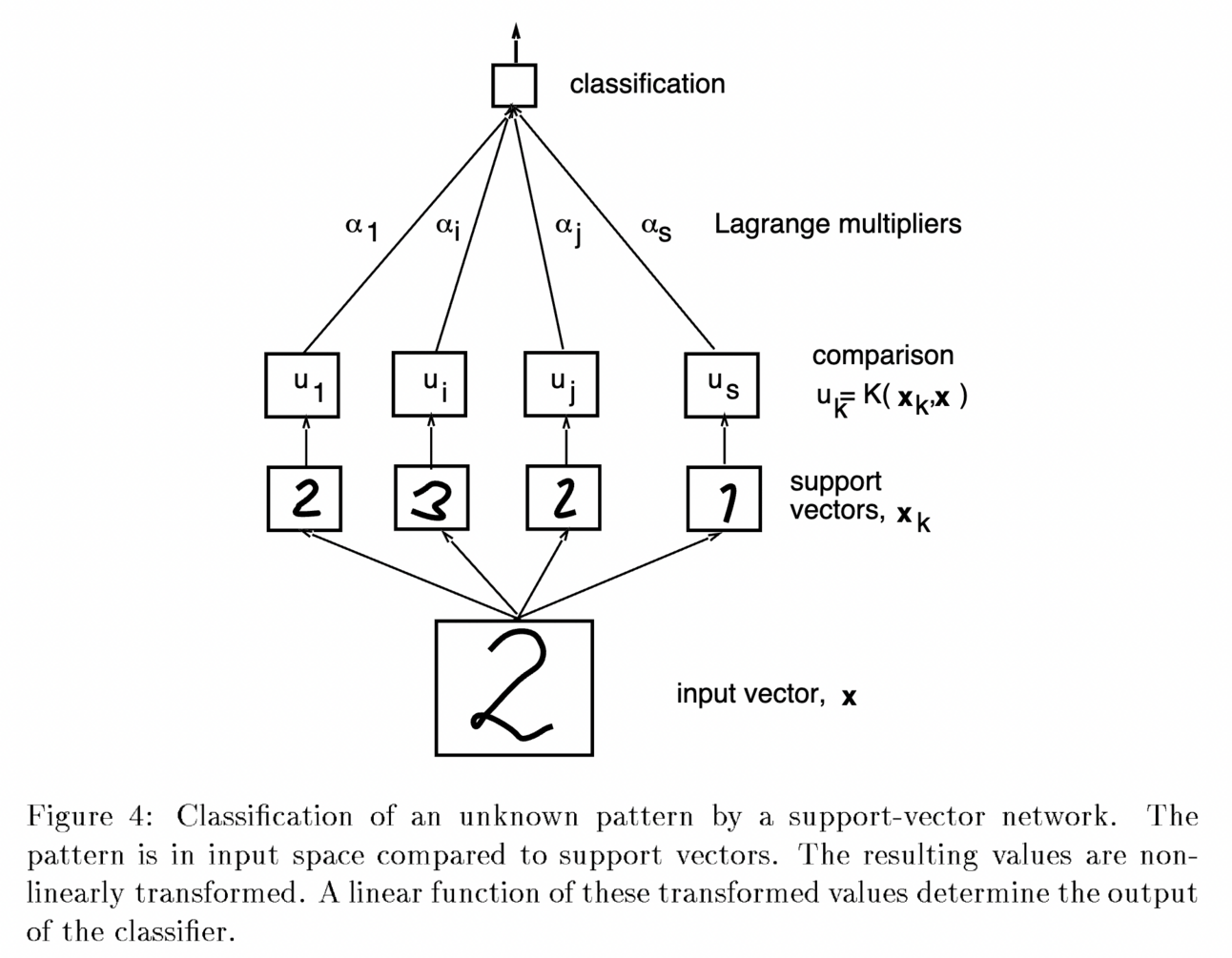
Illustration from C. Cortes; V. Vapnik (1995), "Support-vector networks"
Significant progress was made with Reinforcement Learning (RL). Notable developments included the TD-Gammon program, which achieved superhuman performance in the game of backgammon.

TD Gammon program developed by Gerald Tesauro


Bayesian Networks gained significant attention in the 1990s as a graphical model for probabilistic reasoning and decision-making. Researchers focused on various aspects, such as learning the structure and parameters of networks and developing efficient inference algorithms.
Long Short-Term Memory (LSTM), a deep learning technique for speech recognition, was described by Jürgen Schmidhuber and Sepp Hochreiter in 1997. LSTM can learn tasks requiring memory of events that occurred thousands of steps earlier, making it crucial for speech processing.
Text management tasks, such as information extraction and automatic summarization, gained attention due to the abundance of text on the World Wide Web. Strategies involving word frequency, discourse structure cues, and spoken language processing emerged as practical solutions.
All these works laid the foundation for modern language models. But that was not it!
1999: The Great and Powerful Graphics Processing Units (GPUs)
In 1999, deep learning underwent a significant advancement as computers became faster and Graphics Processing Units (GPUs) were developed. GPUs accelerated computational speeds by 1000 times over a decade, allowing neural networks to compete with support vector machines. Despite the initial slower processing, neural networks yielded better results using the same data. Their ability to continually improve with more training data gave them an advantage.

NVIDIA GeForce 256, released in 1999
The advent of big data (for data to be eligible to be called big, it needs to fulfill three core attributes: Volume, Velocity, and Variety) transformed the landscape by providing access to massive datasets from diverse sources like first social media and sensors. ML algorithms leveraged these datasets for training, enabling the discovery of complex patterns and more accurate predictions.
Simultaneously, advancements in data storage and processing technologies, such as Hadoop and Spark, facilitated efficient processing and analysis of large datasets. These developments led to the emergence of deep learning algorithms capable of learning from extensive data and delivering highly accurate predictions. Let’s move to the 2000s!
The 2000s to 2018: NLMs, Word3Vec, Attention is all you need, and first pre-trained language models
The 2000s witnessed a significant shift in language modeling with the emergence of neural networks. Neural Language Models (NLMs) introduced a novel approach to representing and understanding language, departing from traditional statistical methods.
“The current LLMs are a direct descendant of RNNLM which started all of this, but not many people are aware of it” plus Word Embeddings*, and Word2Vec
Unlike statistical models that treat words as discrete units, neural models encode words as vectors in a high-dimensional space. Similar words are positioned closely in this space, enabling the model to generalize from one word to similar words. That was a much-needed leap!
Bengio et al.'s Neural Probabilistic Language Model (2003) was one of the pioneering neural language models. It introduced the concept of learning distributed word representations and a probability function for word sequences, which was a groundbreaking idea at the time. This model paved the way for the development of more advanced neural language models.

From Bengio et al.'s Neural Probabilistic Language Model
*Word embeddings are dense vector representations of words that capture semantic and syntactic relationships, enabling machines to understand and reason about language in natural language processing tasks.When we asked Tomas Mikolov, the creator of Word2Vec, about that period and how LLMs became possible, he told us that:
“The current LLMs are a direct descendant of RNNLM which started all of this, but not many people are aware of it.
Word2vec itself was only an optimized subset of my previous project – Recurrent Neural Network Language Modeling (RNNLM). The first version of RNNLM was published already in 2010 as an open-source project, and it was the very first publicly available tool for training neural language models. It also contained functionality for generating text – I was the first person in the world to do this.
Probably the most significant result was that with more training data, the neural language models with optimal hyper-parameters were beating n-gram models by increasing margin. Ie. the more data, the more improvement – this is what convinced me that the future of language modeling will be all about neural networks.
In 2012 I joined Google Brain with the intention to make neural language models more popular. They were slow to train, but otherwise excellent. Word2vec (2013) was then my first project at Google to show the power of distributed representations. It was also much faster to train than full language models, so it could have been trained on hundreds of billions of words on a single machine."
Glad we clarified that!

Word2vec Architectures
Word2Vec revolutionized the capture of semantic and syntactic relationships between words, even enabling analogy reasoning (e.g., "man is to king as woman is to queen"). It effectively addressed the dimensionality problem faced by statistical models by representing words in a dense vector space instead of a sparse high-dimensional space.
With these advancements in neural language models and word embeddings, NLP truly rocked. It became possible to capture longer-range dependencies compared to n-gram models* and comprehend the semantic and syntactic relationships between words. Consequently, these developments led to notable performance improvements across various NLP tasks.

N-gram models
n-gram model is a language model that predicts words or sequences of words based on patterns observed in a text.2017: It turned out, Attention is All You Need, indeed
While previously attention mechanisms were typically used alongside recurrent networks, the research paper "Attention is All You Need" introduced the Transformer architecture, which solely relies on an attention mechanism* to capture global dependencies between input and output. Because of LLMs, this paper probably became one of the most known.
*attention mechanism in sequence2sequence (sec2sec) models helps the model pay attention to important parts of the input sequence (words, digits, etc) while generating the coherent output. Usually used in machine translation, text generation, question answering, etc
This mechanism is particularly effective in capturing long-range dependencies in text. Unlike traditional models like RNNs and LSTMs, which struggle with longer sequences, Transformers excel at directly attending to any position in the input, irrespective of its distance from the current position. Consequently, Transformers can handle larger text sequences and capture dependencies spanning extensive gaps.

Parallelizability is another significant advantage of the Transformer model. Unlike sequential processing in RNNs and LSTMs, Transformers can process all positions in the sequence simultaneously, taking advantage of modern hardware's computational efficiency, such as GPUs optimized for parallel computation.
Additionally, the Transformer model introduced positional encoding, a technique that conveys information about the relative positions of words in the sequence. This compensates for the lack of inherent order understanding in Transformers due to their parallel nature, in contrast to RNNs and LSTMs.
The Transformer model has laid the foundation for subsequent NLP models, including BERT, GPT-2, GPT-3, and other modern language models. These models have further developed and expanded upon the Transformer architecture, leading to significant performance improvements across various tasks. The impact of the Transformer model and attention mechanisms in NLP is immeasurable.
Pre-trained language models
Pre-trained models have been a significant development in the field of NLP. They emerged as a result of advancements in deep learning and the availability of large-scale datasets. ELMo (Embeddings from Language Models), one of the early attempts, aimed to capture context-aware word representations. Instead of relying on fixed word representations, ELMo pre-trained a bidirectional LSTM (biLSTM) network. The biLSTM network was then fine-tuned for specific downstream tasks.
Another important pre-trained model is BERT, which is built upon the parallelizable Transformer architecture with self-attention mechanisms. BERT takes the concept of pre-training further by pre-training bidirectional language models using specially designed tasks on large-scale unlabeled corpora. The resulting context-aware word representations have proven to be highly effective as general-purpose semantic features, greatly enhancing the performance of NLP tasks.

The success of ELMo and BERT inspired further research and development within the "pre-training and fine-tuning" learning paradigm. This approach has revolutionized NLP, offering powerful pre-trained models that can be customized and fine-tuned for various applications. Numerous studies on Pre-trained Language Models (PLMs) have emerged, introducing different architectures like GPT-2 and BART, along with improved pre-training strategies.
History of LLMs by Turing Post:
To be continued…
If you liked this issue, subscribe to receive the third episode of the History of LLMs straight to your inbox. Oh, and please, share this article with your friends and colleagues. Because... To fundamentally push the research frontier forward, one needs to thoroughly understand what has been attempted in history and why current models exist in present forms.





