
Was this email forwarded to you? Forward it also to a friend or a colleague! Sign up
Update from 11.07.2025:
Liquid AI is advancing once again with the release of LFM2, a new class of Liquid models designed to be fast, memory-efficient, and usable on any device. These compact models set a new standard among similarly-sized modelss across benchmarks in knowledge, math, instruction following, and multilingual tasks. LFM2 delivers 2× faster CPU decode and prefill than Qwen3 and was trained 3× faster than previous Liquid models.
LFM2 features a novel hybrid architecture including 16 blocks:
10 double-gated short convolution blocks, which act as fast, localized filters. They use multiplicative gates that adapt to the input, enabling dynamic, low-memory processing.
6 grouped query attention (GQA) blocks that add longer-range context.
Below, discover what’s under the hood of Liquid models and the technologies that fuel their workflow.
The most important features of LFMs? Memory-efficiency, inference speed, without compromising model quality. Transformers have been around for years and are highly optimized. New architectures tend to work well on paper against a vanilla Transformer, but not compared with the modern versions with FlashAttention. This is not the case with LFMs that have been benchmarked on real hardware. This has interesting implications, for example faster and more memory-efficient reasoning.
Liquid AI just released their new Hyena Edge family, plus they are working on something even more interesting. It’s time for more people to learn about this architecture and their innovative approaches. Some say Transformers have set the pace – and no one dares step in their way. The attention mechanism made Transformers famous – and for good reason. It helped models link different parts of the input and powered many of AI’s biggest breakthroughs. But (there’s always a but): attention doesn’t scale well. As sequences get longer, models tend to slow down and use more memory, with compute costs increasing quickly. This makes it harder to work with long texts, music, or large datasets. Breaking this barrier could unlock faster, more efficient models — able to process massive sequences on everything from datacenters to your phone. What if we dropped attention altogether – and used a system built to process long sequences like a signal evolving through time: stable, fast, and context-aware?
That’s what Liquid AI’s research team is trying to achieve.
Today we’ll look at the first of their Liquid Foundation Models (LFMs) – how it moves beyond attention with a dynamic system built for continuous input, and how that opens up new ways to handle long-form data. We’ll also explore the more experimental Hyena architecture, which replaces attention with fast convolutions and gating, and see how it’s adapted in Hyena Edge – a version designed to run efficiently on smaller devices like your phone, without giving up quality or context awareness. Let’s dive into Liquid AI’s history, how they build intelligence at every scale, and their potential for beating Transformers. And if they have that potential – why aren’t LFMs widely used?
Follow us on 🎥 YouTube Twitter Hugging Face 🤗
In today’s episode, we will cover:
How it all began: Liquid Neural Networks
What are Liquid Foundation Models (LFMs)?
What makes LFMs special?
So how does it perform?! And other benefits of LFMs
Why aren’t they widely used?
What is Hyena operator and Hyena Edge?
How exactly was Hyena Edge build? The role of STAR
Results of Hyena Edge
Are emergent behaviours expected in Hyena Edge?
Conclusion
Sources and further reading
How it all began: Liquid Neural Networks
Liquid AI was founded in 2022 from deep scientific research at MIT and related academic collaborations. Four founders – Ramin Hasani, Mathias Lechner, Alexander Amini, and Daniela Rus, started Liquid AI to create a new generation of foundation models from first principles.
But the first waves of innovation came before this, when a team led by Ramin Hasani during his Ph.D. research at MIT CSAIL, including researchers that later became Liquid AI co-founders and others, was inventing Liquid Neural Networks (LNNs) from 2016 to 2020.
Inspired by how the brain processes information, the team aimed to create AI systems, that would break the law and claim that scaling is not everything that we need. They focused on continuous-time adaptability – making LNNs adaptable even after training.
After their invention, the team proved LNNs could do amazing things:
They were universal approximators, modeling any pattern given enough data.
They could efficiently handle sequential and time-dependent data, like video, audio, and long conversations.
They were interpretable, meaning researchers could actually understand why they made certain decisions.
They were causal, handling cause-effect relationships more naturally than traditional models.
Their work expanded to neural differential equations, graph neural networks, scaling AI architectures for real-world hardware, proving that Liquid-style AI wasn’t just theory.
At the same time, in 2021-2022, the AI world was obsessed with scaling Transformers. But, as we all know, they are not ideal: they are too rigid, too memory-hungry, and not adaptive.
With the aim of building dynamic, efficient, and powerful models at every scale using new principles, rather than simply stacking more GPUs, the team finally launched Liquid AI in 2022.
What are Liquid Foundation Models (LFMs)?
Upgrade to receive the full articles with detailed explanations and curated resources directly in your inbox. Join executives from Microsoft, Hugging Face, Nvidia, Snowflake, Google, AllenAI, MIT, Columbia, and thousands of others who find Turing Post extremely useful – on both strategic and technical fronts →
Launching a family of models takes serious work – research, training, evaluation, fine-tuning, infrastructure, deployment. it took two years for Liquid AI to launch the first version of Liquid Foundation Models (LFMs) in September 2024. LFMs aim to reimagine how foundation model function, using insights from liquid neural networks, signal processing, differential equations, and efficient hardware design. They were built from first principles – meaning the team didn’t modify Transformers but started from scratch, focusing on the core problem: how to model sequences efficiently without relying on attention. Now, LFMs are released in four sizes: 1B, 3B, 40B and the latest one 7B.
Under the hood, LFMs rely on structured operators rooted in dynamical-systems math, signal filters, and linear-algebra tricks. In practice, this means integrating components like long convolutions that capture distant patterns, gating functions that keep information stable over thousands of steps, and continuous state-space dynamics – together called linear input-varying systems, or LIVs – slotted alongside (or in many layers instead of) classic self-attention. This chemistry lets the network treat text, audio, video, sensor feeds, or financial time series as one flowing signal, adapting its computation in real time the way liquid changes shape. Let’s unpack how that workflow comes together during training and why it scales so smoothly across data types and device sizes.
What makes LFMs special?
Modular architecture with shared structure
LFMs organize their computational units into depth-based groups. Within each group, some weights are reused to reduce redundancy. Features can also flow between groups through featurizer interconnections, which strengthens internal connectivity. This setup makes the architecture modular, compact, and easier to adapt across different tasks and hardware.
Image Credit: Liquid Foundation Models blog post
Built-in featurization
Before processing even begins, LFMs analyze the input – whether it’s text, audio, or video – and extract structured features. These act as control signals, influencing how each unit operates. As a result, the model dynamically adjusts to different data types, tuning itself based on the nature of the input (e.g., a paragraph vs. a time series).Dual-mode information mixing
Each LFM unit processes information in two key ways:Token-mixing, which blends input across positions (e.g., how words relate in a sentence).
Channel-mixing, which blends across feature dimensions (e.g., grammar, tone, or signal patterns).
These two modes work together to build a layered understanding across time, structure, and meaning – efficiently and in context.

Also, one of LFMs’ big innovations is that they compress information as it flows, rather than having memory grow with every token as in Transformers. So LFMs can handle up to 1M tokens without exploding memory or slowing down, achieving minimal memory footprint, and can better "remember" important parts of input.
So LFMs need much less memory to run. For example, the LFM-3B only needs 16 GB of memory, while Meta’s similar model needs 48 GB, which makes them perfect for edge devices, like phones, where memory is limited.

Image Credit: Liquid Foundation Models blog post
We also asked Maxime Labonne, the Head of Post-Training at Liquid AI, to conclude what the most important features of LFMs are 👇
Memory-efficiency, inference speed, without compromising model quality. Transformers have been around for years and are highly optimized. New architectures tend to work well on paper against a vanilla Transformer, but not compared with the modern versions with FlashAttention. This is not the case with LFMs that have been benchmarked on real hardware. This has interesting implications, for example faster and more memory-efficient reasoning.
So how does it perform?! And other benefits of LFMs
Liquid AI claims state-of-the-art (SOTA) performance for LFMs at each size:
LFM-1B: Achieves highest scores across many language benchmarks in the 1B parameter class, outperforming all comparable 1B models.
LFM-3B: Ranks first among 3B models and even surpasses some previous 7B–13B models. It’s also on par with a Phi-3.5 model from Microsoft while being ~18% smaller. LFM-3B is ideal for mobile/edge applications, hinting at efficiency.
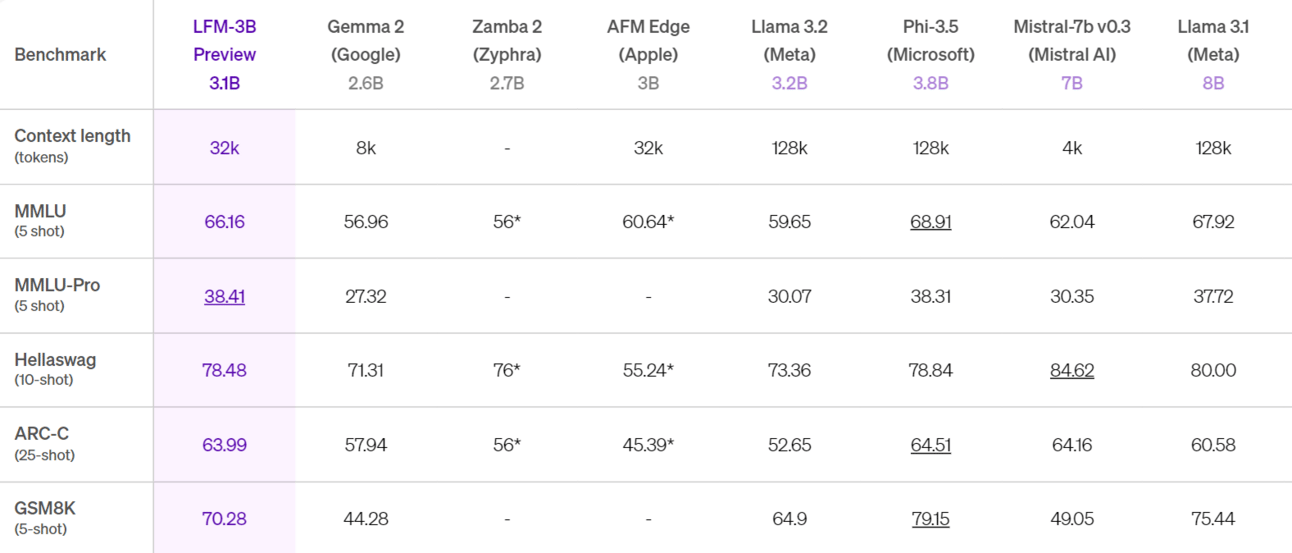
Image Credit: Liquid Foundation Models blog post
LFM-40B (MoE): Uses 40B total parameters with only 12B active at inference due to MoE sparsity. It delivers quality comparable to larger 50–70B models while enabling higher throughput and cheaper deployment. For example, on the MMLU academic benchmark (5-shot), LFM-40B scores ~78.8, close to or exceeding models like Meta’s Llama 3.1 (70B). This demonstrates that smart architecture (MoE + LIV units) can beat brute-force scale.
LFM-7B: It’s a multilingual model, optimized to “think natively” and have great conversations across English, Arabic, Japanese. LFM-7B beats every other 7B-8B model in business conversations, following complex instructions and real-world chat situations. It also supports Spanish, French, German, Chinese, and Korean at high quality.
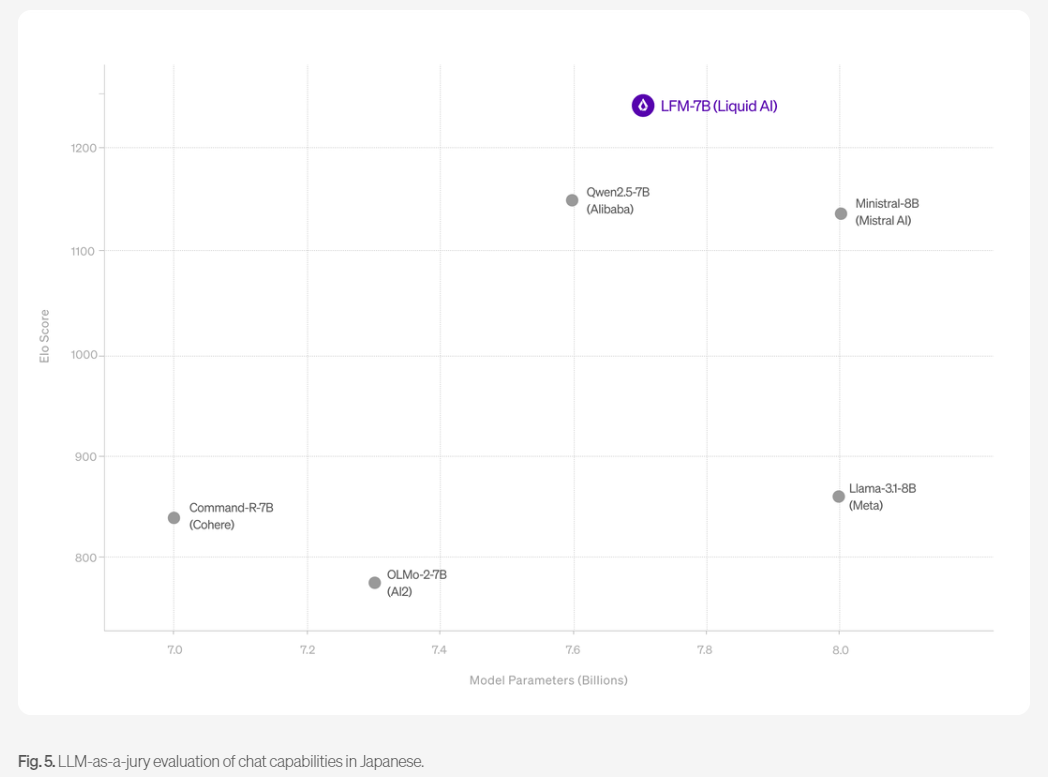
Image Credit: Liquid Foundation Models blog post


The benchmarks back up Liquid’s claim: fresh architectural ideas can rival raw scale. LFMs post strong scores with comparatively few parameters, challenging the bigger-is-better Transformer mindset.
To sum up, here are the main advantages LFMs offer:
They process input by efficiently flowing through their computational units.
As memory footprint doesn’t grow as much, LFMs stay fast and stable even for long conversations.
They produce answers with lower delay and less hardware demand compared to standard large models.
Whether you're using a NVIDIA GPU, a Qualcomm chip in a smartphone, or a Cerebras wafer-scale engine, the model can adapt.
The architecture can be automatically optimized for the memory, compute, and energy needs of the device.
This adaptability is a huge part of why LFMs are so exciting for both enterprise servers and mobile devices. But…
Why are they not widely used?
Well, there are several reasons why LFMs still fly under the radar:
Transformers were first to catch everyones attention (!). Right now, everything, like libraries, hardware, datasets, benchmarks, fine-tuning techniques, is optimized for Transformers, so it’s just more convenient to work with them.
Adoption lags behind innovation – it usually takes some years for brand-new model architectures to be widely adopted. LFMs use different mathematics (dynamical systems, signal processing, adaptive operators) instead of self-attention, so they require other techniques and relearning to working with them. Building a full ecosystem takes time.
Liquid AI has not fully open-sourced their LFMs yet. While they offer API access (Liquid Playground, Lambda Labs, Perplexity Labs), developers can't download and fine-tune LFMs freely like they can with, for example, LLaMA or Mistral models.
Liquid AI is going to solve the last issue – they plan to open source LFMs in the coming months including the newest Hyena Edge, which is a newcomer in the LFM family. We wonder if that would be possible to have a llama moment for them if open-sourcing? Will hyena eat llama? We hope the naming was with that in mind! Anyway, let’s discuss what is new and special about Hyena Edge?
What is Hyena operator and Hyena Edge?
Hyena Edge, released on April 25, is a lightweight model optimized for on-device inference – designed to run efficiently on smartphones, laptops, and other resource-constrained devices. Its architecture is built around a convolution-based multi-hybrid design. The name “Hyena” comes from the Hyena operator, a signal processing-inspired alternative to the attention mechanism used in Transformers.
At its core, Hyena consists of two main components:
Long convolutions, which mix information across the entire input sequence.
Gating mechanisms, which determine what to keep or discard based on the input itself.
These two steps repeat throughout the model, helping it capture complex patterns and relationships over long stretches of data.
What makes Hyena unique is how it handles memory and pattern recognition. The convolution layers use special filters – mathematical functions that decide how to mix and retain input signals. These filters aren’t fixed; they’re learned by a small neural network, allowing the model to adapt based on the task. It can tune itself to recognize slow-changing trends, sharp shifts, or subtle signal variations, depending on the context.
The result is a model that can replace attention layers while achieving efficient long-range modeling – with much lower time and memory costs, especially at longer sequence lengths.

Image Credit: Hyena Hierarchy: Towards Larger Convolutional Language Models
Hyena Edge is a convolutional multi-hybrid model – meaning it doesn’t rely on a single operator but combines several, including Hyena-like components and Transformer elements. This hybrid setup is intentional: it’s designed to make the most of modern hardware like GPUs by using each layer type where it performs best, balancing efficiency with performance.
How exactly was Hyena Edge build? The role of STAR
Another interesting detail: Hyena Edge was designed using Liquid AI’s automated architecture system called STAR (Synthesis of Tailored Architectures). Think of it as a smart architect, but for neural networks – it evolves model designs over time. Like natural selection, STAR explores hundreds of combinations of components such as attention, convolutions, and recurrence – collectively known as LIVs (Linear Input-Varying Systems). Each model design is encoded as a numeric “genome,” and STAR evolves these genomes over successive generations by selecting top performers, recombining them, and refining the designs to meet specific performance goals like speed and memory efficiency.

Image Credit: STAR: Synthesis of Tailored Architectures original paper
In the case of Hyena Edge, after 24 generations, STAR found a design that balanced speed, memory, and performance perfectly for edge deployment.
Three Hyena variants were explored during STAR’s design process:
Hyena (full): Has convolutions in both inner and gating mechanisms.
Hyena-X: Excludes the inner convolution.
Hyena-Y: Removes convolutions from the gating feature groups.
The last one, Hyena-Y, stood out thanks to best tradeoff between speed, quality, and memory use. So, in the final Hyena Edge model, two-thirds of the attention blocks were replaced with Hyena-Y convolutions.
Hyena Edge is also remarkable as a proof point that STAR system can yield deployable models.
Results of Hyena Edge
The hybrid design gave Hyena Edge the speed of lightweight models, but with the intelligence of much larger ones. In tests on the Samsung S24 Ultra, Hyena Edge:
Had up to 30% lower latency than top Transformer-based models. It ran faster during both the setup (prefill) and reply (decode) phases at 256+ tokens.
Outperformed the GQA-Transformer++ baseline on all tasks, such as Wikitext, Lambada, Hellaswag, Winogrande, Piqa, Arc-easy, and Arc-challenge, achieving lower perplexity and higher accuracy.
Handled both short prompts and longer conversations better.
Used less memory at every sequence length thanks to no quadratic attention overhead, efficient convolution design, optimized operator fusion and execution path.

Image Credit: Hyena Edge blog post
Speaking specifically about the difference of Hybrid Edge and Transformers’ scaling behavior, Maxime Labonne approved:
Yes, there are definitely different scaling behaviors for different architectures. In the MAD paper, we show for example that Hyena-based hybrid models exhibit better scaling behaviour than Transformers, achieving meaningfully better perplexity at the same compute budget/the same perplexity at less compute.
Indeed, when using the same amount of compute, hybrids in general perform better than Transformers. While Transformers tend to benefit more from being big, hybrids benefit more from longer training of smaller models with more data.
Hybrids can also match or beat Transformers, while using less memory. The correlation is also strong and consistent, even across different architectures like Hyena and Mamba.

Image Credit: “Mechanistic Design and Scaling of Hybrid Architectures” original paper
Also, Transformers are appreciated because they demonstrate emergent behaviours, like in-context learning or multi-step reasoning, that arise unexpectedly as model scale increases, even though the model wasn’t explicitly trained for them.
Are emergent behaviours expected in Hyena Edge?
We don’t expect emergent behaviours. Our key goal with Hyena Edge is to match or outperform Transformers in quality (we always aim for best in class) at much better hardware efficiency.
This clear and concrete direction, where developers know what they want to achieve in the end, is also a benefit of Hyena Edge.
Conclusion
Liquid AI’s LFMs — and especially Hyena Edge — offer a practical example of what rethinking model architecture can lead to. Instead of scaling up, they focused on making models more efficient, more adaptable, and easier to run on real hardware, including edge devices.
It’s still early. Most of the ecosystem is built around Transformers, and it takes time for new architectures to gain traction. But LFMs show that there are other paths worth exploring — ones that can deliver strong results without the usual memory and compute overhead.
Whether or not Hyena Edge becomes widely adopted, it points to a broader shift: away from pure scale, and toward smarter, more deliberate design.
Looking forward to seeing Liquid AI open-source their models!
Sources and further reading
Convolutional Multi-Hybrids for Edge Devices (blog post)




