
This Week in Turing Post:
Wednesday – AI 101 / Concept: What Reasoning Models Really Are
Friday – Agentic workflow: Reward Hacking – an excellent topic to explore in more depth
Our news digest is always free. Upgrade to receive our deep dives in full, directly into your inbox. If you want to support us without getting a subscription – do it here.
Two main topics today!
Apple, agent wars on-device, and security questions
I was thinking about everyone trashing AI after last week’s introduction of Liquid Glass and the delay of advanced Siri. But what if Apple Intelligence isn’t about using third-party large models at all – what if it’s about turning Apple devices into little data factories and agents hosts that work for their owners? That’s a pretty cool idea.
With that idea in mind, it might be that Apple may have just triggered a major realignment in how agentic AI gets built and deployed. By opening its on-device model to developers, it’s inviting a new generation of apps that don’t run in the cloud, don’t stream user data, and don’t need an OpenAI key. The model lives in the OS. The runtime belongs to the user. But that raises an obvious next question: if developers can access the model, what happens to security?
There are two parts to this.
First, access doesn’t mean transparency. Developers can call Apple’s proprietary model – ask it to summarize a note, answer a question, or generate text – but they don’t see the model’s memory, weights, or user context. Apple is keeping the context layer private. In this setup, the device acts as an execution environment. Developers send a prompt; the model responds. But the state remains on the device, and outside developer reach. This is very different from cloud-based APIs where devs can log everything.
Second, Apple is betting on sandboxing + App Store policy. If a developer tries to misuse the runtime – say, to trick the model into leaking personal information or calling external tools without permission – Apple can block that behavior at the OS or review level. It’s not foolproof, but it puts control at the software layer, rather than hoping users navigate privacy popups correctly.
The bigger risk is behavioral, not technical: will developers try to re-centralize this model by chaining local outputs to cloud services anyway? Will they proxy the model’s reasoning through external APIs? That’s where policy and UX defaults matter. Apple has strong leverage here. They can encourage workflows that stay on-device – and penalize apps that abuse access.
So yes, the “Agent Wars” may shift from cloud to device. But only if the developer layer stays aligned with the user’s interest. Will see how that unfolds, but Apple’s move indicates the importance of small models once again!
Signals from Sam Altman most people missed
I argue that his article The Gentle Singularity isn’t really about digital singularity – it’s a vision for a full-blown cyber-physical ecosystem. No wonder Nvidia now pegs physical AI as a $50 trillion opportunity. In that sense, MIT’s new paper, “Self-Adapting Language Models”, is a must-read: it offers a blueprint for autonomous systems that learn on the fly – an essential building block for that ecosystem.
Anyway, watch the thinking process and DO let me know what you think →
From our partners
🔹 Ready to accelerate your AI innovation? The time is now.

Join us for Accelerating AI Innovation, a virtual event where CoreWeave, NVIDIA, and some of the planet's most cutting-edge AI pioneers and luminaries will share their real-world, hard-earned insights on all the AI topics that matter most to your business. From founders to ML engineers – if you're building with AI, this is your moment. Seize it now.
New Cool model + Curated Collections
Since researchers from Meta just introduced V-JEPA 2, a self-supervised world model trained on 62 hours of robot data from the Droid dataset and large-scale natural video, We decided to share two collections of different JEPAs that we put together recently. Enjoy!
About V-JEPA 2: It excels at motion understanding, visual reasoning, and future-state prediction. Using a two-phase training strategy, it enables zero-shot robotic control –completing tasks like reaching and grasping from only goal images. V-JEPA 2 sets a new benchmark in planning for unfamiliar environments without task-specific robot demonstrations. Check out our latest collection →

Follow us on 🎥 YouTube Twitter Hugging Face 🤗
We are reading/watching
How we build our multi agent research system by Anthropic
Meta + Scale AI?, Meta’s Reset, AI as Sustaining Innovation by Stratechery
Let’s talk AI exits by Madrona
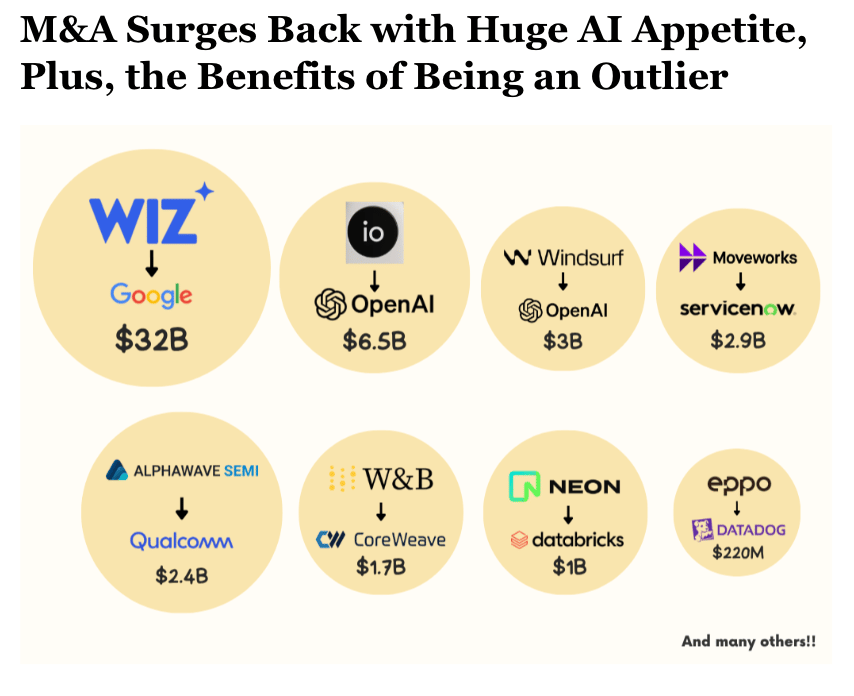

News from The Usual Suspects ©
Hugging Face insists, “Bigger isn’t better”
Nvidia’s Jensen Huang: “I disagree with almost everything he says”
Jensen Huang isn't mincing words. At VivaTech in Paris, the Nvidia CEO took aim at Anthropic’s Dario Amodei, scoffing at his dire predictions about AI replacing half of entry-level jobs. Huang argues for open, responsible development – not “dark room” AI monopolies. Yann LeCun agrees→

Meta’s Superintelligence Gambit
Meta is assembling a new AI lab aimed squarely at “superintelligence,” with Scale AI’s Alexandr Wang reportedly in the driver’s seat. The move is part of a broader AI shakeup at Zuckerberg HQ, where staff churn and awkward product flops have made headlines. Meta is betting big – again – but this time it’s not just chasing AGI, it’s gunning for the next rung up the ladder.Google Talks Back
Google’s latest Labs experiment adds a voice to Search. “Audio Overviews” uses Gemini to turn certain queries into short, spoken summaries – ideal if you're juggling tasks or just tired of reading. Available now in Labs for the curious and the multitaskers.OpenAI: brains to Barbie and to Projects
Mattel and OpenAI are teaming up to bring AI into the toy chest. Expect smarter, safer, and more imaginative play experiences as Mattel plugs into ChatGPT Enterprise to drive product innovation and operational flair. First toys from this collab are expected later this year.
ChatGPT’s June 2025 upgrades bring serious muscle to Projects. Deep research across web and files, voice chat, mobile file uploads, and smarter memory make this very convenient for long-haul work. It's free with Plus, Pro, and Team plans.
Models and datasets to pay attention to:
An incredible dataset: 🌟Institutional Books 1.0: A 242B token dataset from Harvard Library's collections, refined for accuracy and usability
Sourced from 1,075,899 scanned books across 250+ languages via the Google Books project, the dataset includes both raw and post-processed text and detailed metadata. It emphasizes transparency, provenance, and accessibility, aiming to support responsible LLM development with high-quality, sustainable historical text resources →read the paper🌟o3-pro from OpenAI, a high-reliability LLM optimized for math, science, and coding. It outperformed o1-pro and o3 in academic and expert evaluations, achieving top scores in clarity, instruction-following, and accuracy. It includes tool access (e.g., web search, code execution, vision), but with slower response times. o3-pro replaces o1-pro for Pro and Team users →read their blog (they also drop the price of o3 by 80%)


🌟FGN from Google DeepMind, a new ensemble-based probabilistic forecasting method. It models both aleatoric and epistemic uncertainty, yielding stronger calibration and more accurate tropical cyclone track predictions than prior models (like GenCast and ECMWF ENS). It marks a significant step in data-driven weather forecasting.
Magistral from Mistral trains LLMs from scratch using pure reinforcement learning on text, showing that reasoning, multimodal understanding, and function calling can be retained or improved without distillation ->read the paper
Resa: Transparent Reasoning Models via SAEs boosts reasoning with sparse autoencoders that extract and transfer capabilities across models, enabling efficient and modular reasoning augmentation ->read the paper
Multiverse (Carnegie+NVIDIA) reimagines generation via native parallel reasoning using a MapReduce-inspired attention mechanism, matching autoregressive LLM performance with higher efficiency ->read the paper
Ming-Omni combines unified encoders and modality-specific routing to handle images, text, video, and audio in one model, supporting generation, editing, and chat across all modalities ->read the paper
Seedance 1.0 by ByteDance achieves state-of-the-art video generation through high-quality data curation, hybrid diffusion training, post-training RLHF, and system-level speed optimizations ->read the paper
Sentinel detects prompt injection attacks with high precision using a fine-tuned ModernBERT-based classifier trained on a diverse dataset of malicious and benign instructions ->read the paper
The freshest research papers, categorized for your convenience
We organize research papers by goal-oriented or functional categories to make it easier to explore related developments and compare approaches. As always, papers we particularly recommend are marked with 🌟
Theoretical Perspectives
🌟 Large Language Models and Emergence: A Complex Systems Perspective reexamines emergence in LLMs through the lens of complexity science, distinguishing between emergent capability and emergent intelligence ->read the paper
Agentic Systems and Autonomous Behavior
AutoMind: Adaptive Knowledgeable Agent for Automated Data Science builds a flexible agent that integrates expert knowledge, search-based strategy, and adaptive code to automate real-world data science workflows ->read the paper
Thinking vs. Doing: Agents that Reason by Scaling Test-Time Interaction improves web agent performance by allowing longer, adaptive test-time interactions instead of static reasoning traces ->read the paper
🌟 Build the Web for Agents, not Agents for the Web proposes a redesign of web interfaces to better support agent navigation, focusing on safety, standardization, and agent-native affordances ->read the paper See also: how Webflow's CEO is already building for this shift in practice.
Code Researcher: Deep Research Agent for Large Systems Code and Commit History creates a multi-phase agent that researches code, commit history, and crashes to synthesize and validate patches for large codebases ->read the paper
Learning Paradigms and Pretraining Innovations
🌟 Reinforcement Pre-Training reframes next-token prediction as an RL task, enabling scalable reasoning-driven pretraining across massive text data ->read the paper
VerIF: Verification Engineering for Reinforcement Learning in Instruction Following combines rule-based and LLM-based verifiers to guide instruction-tuned RL and improve generalization ->read the paper
Compound AI Systems Optimization: A Survey about optimization strategies for multi-component AI systems, emphasizing language feedback and integration challenges ->read the paper
Reasoning and Planning Models
ComfyUI-R1: Exploring Reasoning Models for Workflow Generation automates creative workflow generation through long chain-of-thought reasoning and reinforcement learning in modular image synthesis systems ->read the paper
RuleReasoner: Reinforced Rule-based Reasoning via Domain-aware Dynamic Sampling boosts small model reasoning over symbolic rules using a domain-aware RL strategy for efficient generalization ->read the paper
SeerAttention-R: Sparse Attention Adaptation for Long Reasoning speeds up long reasoning tasks via a sparse attention mechanism optimized for autoregressive decoding ->read the paper
Through the Valley: Path to Effective Long CoT Training for Small Language Models reveals how long chain-of-thought training degrades small models and how extensive fine-tuning can partially recover performance ->read the paper
Give Me FP32 or Give Me Death? Challenges and Solutions for Reproducible Reasoning analyzes how floating-point precision and hardware configurations destabilize reasoning chains in LLMs, proposing a more stable inference pipeline ->read the paper
🌟 Play to Generalize: Learning to Reason Through Game Play
Enhances multimodal reasoning by post-training MLLMs through gameplay without domain-specific data ->read the paper
Infrastructure and Scaling Strategies
NoLoCo: No-all-reduce Low Communication Training Method for Large Models eliminates parameter synchronization overhead in distributed training, enabling faster convergence with lower hardware demands ->read the paper
🌟 Position: Scaling LLM Agents Requires Asymptotic Analysis with LLM Primitives argues for analyzing multi-agent LLM systems using cost-based asymptotic reasoning instead of anthropomorphic decomposition ->read the paper
Model Adaptation and Specialization
Text-to-LoRA: Instant Transformer Adaption enables LLMs to rapidly specialize for new tasks using natural language descriptions, generating LoRA adapters in a single forward pass ->read the paper
Domain2Vec: Vectorizing Datasets to Find the Optimal Data Mixture without Training decomposes datasets into meta-domains to guide training mixture optimization without retraining, improving compute efficiency and downstream performance ->read the paper
ConfQA: Answer Only If You Are Confident reduces hallucinations in factual LLM outputs by fine-tuning with confidence-aware prompts and symbolic knowledge grounding ->read the paper
Data Processing and Retrieval-Augmented Reasoning
TableRAG: A Retrieval Augmented Generation Framework for Heterogeneous Document Reasoning combines SQL-based tabular reasoning with text retrieval for better question answering over mixed documents ->read the paper
Attention, Please! Revisiting Attentive Probing for Masked Image Modeling redesigns attention probing for efficient, accurate evaluation of image representations in self-supervised models ->read the paper
→ FOD#106: Don't be passive aggressive with your agents
That’s all for today. Thank you for reading! Please send this newsletter to your colleagues if it can help them enhance their understanding of AI and stay ahead of the curve.




