
This Week in Turing Post:
Wednesday, AI 101: we cover the very hot topic: GPRO and the freshest research paper about Flow-GPRO
Friday, A fascinating interview — “When will we give AI true memory?” with Edo Liberty from Pinecone
You are currently on the free list. Join Premium members from top companies like Hugging Face, Microsoft, Google, a16z, Datadog plus AI labs such as Ai2, MIT, Berkeley, .gov, and thousands of others to really understand what’s going on with AI →
If you want to support us without getting a subscription – do it here.
It’s our hundredth FOD today. 🎉 For those who recently joined us: we started this news digest as an overview of what 150+ newsletters have been musing about. It’s true, every week, I read more than 150 newsletters and skim through ~200+papers to gather the most important signals for you. I call it “Froth on the Daydream" – or simply, FOD. It’s a reference to the surrealistic and experimental novel by Boris Vian – after all, AI is experimental and feels quite surrealistic, and a lot of writing on this topic is just a froth on the daydream.
Today, we’re decoding the AI world through its newest terms. What’s so important about terms? In AI, new terms signal new directions. CTM, Elastic Reasoning, ZeroSearch — these are becoming your newest clues. Clues to how models are evolving, how intelligence is being redefined, and where everything might go next.
Continuous Thought Machines
It always worth watching what Sakana AI is up to. This Tokyo-based AI research startup founded by former Google DeepMind scientists David Ha and Llion Jones. Known for their biologically inspired approach, they focus on evolving and combining small models rather than scaling monoliths. Today, May 12th, they released Continuous Thought Machines (CTM) and asked the right question: what if time is the missing piece in AI?
CTM is a new model that thinks differently – literally. Instead of firing once and moving on, its neurons look back, remember, and sync up. Timing becomes information. Patterns emerge not from layers, but from rhythms. You can watch it work: solving mazes step by step, tracing the path like a person would. Scanning an image, focusing on eyes, then nose, then mouth. There’s no prompt to look this way – it learns to. And the more it thinks, the better it gets. In Sakana’s version: time is no longer a constraint. It’s the medium of thought.
Elastic Reasoning
Salesforce AI has a very strong research team. Last week, they introduced new approach: Elastic Reasoning. It is a fresh take on how LLMs solve problems efficiently. Traditional models generate long chains-of-thought (CoT), but that’s often impractical when compute budgets are tight. This approach smartly splits reasoning into two phases: thinking and solution – each with its own budget (!). Instead of letting the model ramble endlessly, Elastic Reasoning ensures that the final answer is always completed, even if the thinking gets cut short. What makes this novel is its adaptability: once trained under budget constraints, the model generalizes well to new constraints without retraining. It performs better under pressure – less compute, more accuracy –and even becomes more concise in unconstrained settings. That’s rare. With its strong math and coding benchmark results, it could very well become a standard for deploying reasoning LLMs in cost-sensitive, real-world scenarios. In a landscape obsessed with scale, Elastic Reasoning makes restraint a feature – not a flaw. Definitely worth watching.
Week of zeroes
ZeroSearch, introduced by Alibaba’s Tongyi Lab, is new talk of the town. It’s a technically elegant solution to a persistent bottleneck in RAG and agentic reasoning: how to effectively teach search behaviors without relying on unstable, expensive external APIs.
Instead of querying real-world search engines during RL – which incurs high latency, uncontrollable document quality, and prohibitive costs ZeroSearch uses a supervised fine-tuned LLM as a simulated search engine. This model can generate both high-quality and noisy documents in response to queries, enabling fine-grained control over search environments. What's compelling is the curriculum-based degradation strategy, which incrementally increases document noise during RL rollouts to stretch the model’s reasoning ability – a form of progressive domain randomization applied to language.
This framework effectively disentangles retrieval and policy learning, allowing stable gradient flows through the policy while masking retrieval-token loss. Empirically, ZeroSearch’s 14B simulated retriever outperforms Google Search in downstream QA tasks. It’s a scalable, architecture-agnostic training strategy that could redefine how we instill agentic search skills in LLMs – without touching the web.
zero, more zero, most zero – Absolute Zero! Absolute Zero introduces a bold new idea: what if an AI could improve its reasoning without any human-generated data? Instead of learning from curated datasets, it creates its own tasks, solves them, and learns from the outcome – entirely through self-play. If safety challenges are addressed, Absolute Zero could become a foundational method for training autonomous reasoning agents, especially in domains where human supervision is infeasible or insufficient.
Welcome to Monday. Zeroes are cool, but ones are also keeping up! Check the research section to find awesome papers about RL1.
Curated Collections

Follow us on 🎥 YouTube Twitter Hugging Face 🤗
From AI practitioner
Codename Goose – a local-first, open-source AI agent from that builds, runs, and debugs code – no cloud needed. Goose plugs into your dev tools, supports multiple LLMs, and keeps your projects private. It’s refreshingly simple.
We are reading/watching
Casualties of the U.S.-China trade war: humanoid robots by Rest of World
A Potential Path to Safer AI Development by Yoshua Bengio (one of AI godfathers)
Not every conversation with Mark Zukerberg is interesting, this one is: he suggest a few ideas how AI is changing ad world
News from The Usual Suspects © - it’s all about OpenAI today
Saudi Arabia bets on the machine
Crown Prince Mohammed bin Salman has launched Humain, a state-backed company focused on AI development. Their goal is to become a global AI hub. New competitor in town!
FutureHouse, an Eric Schmidt-backed nonprofit that aims to build an “AI scientist” within the next decade, has launched its first major product: a platform and API with AI-powered tools designed to support scientific work.

Image Credit: FutureHouse
Meta (Back to Face Business)
Privacy is out; “super sensing” is in. According to The Information: Meta has quietly resumed work on facial recognition tech for its smart glasses, betting that a lax regulatory climate under Trump’s Federal Trade Commission will keep watchdogs leashed.
Meanwhile, The wall street journal published a fascinating report from Joanna Stern who wore three AI gadgets that recorded everything she said for three months. The Bee, Limitless, and Plaud devices turned her life into searchable transcripts and automatic to-do lists.
Speaking about wearables
Human muscle can act as a data processor using “reservoir computing.” This opens the door to wearables that offload processing to your body, using its natural memory and nonlinear behavior to crunch data.
Amazon Vulcan
Amazon’s Vulcan enters the wearable-adjacent arena with a twist: touch. Vulcan is the first AI-powered warehouse robot that feels – responding to pressure, recognizing objects by handling them, and learning like a child. It’s Physical AI in action, where the body becomes the brain. First wearables used us; now machines are borrowing our senses.
Neuralink [I’m Thinking, Therefore I’m Posting]
Sometimes soon we might wear the devices inside us as naturally as we do with pacemakers or cochlear implants. Neuralink’s brain implant has given Bradford Smith, a man with ALS, the power to create YouTube videos with just his thoughts.
Apple (is iPhone done?)
At an Google Search antitrust remedies trial, Edy Cue suggested AI could do to the iPhone what Apple once did to the iPod – kill it off for something smarter. With smart glasses, AirPods, and watches in the wings, Apple’s future may be voice-first and screen-optional.
and their new chip might help with that! Apple works on a wave of custom chips to power its next-gen ecosystem. As Meta pushes memory-tracking eyewear and Neuralink taps the brain, Apple is betting its future on wearables that quietly think with you.

For more nerdy audience 😎 🤍
Open ai
Remember reinforcement fine-tuning? It’s live for o4-mini. By combining COT reasoning with graded task performance, RFT gives domain-specific models serious IQ boosts. Meanwhile, supervised fine-tuning is now available for GPT-4.1 nano, letting you sculpt OpenAI’s speediest, thriftiest model to your liking. Plus RFT use cases → here
ChatGPT’s deep research agent now reads GitHub repos – code, PRs, and all –returning cited reports on demand. Just connect and ask.
is getting more physical:
Sam tweeted: “great to see progress on the first stargate in abilene with our partners at oracle today. will be the biggest ai training facility in the world. the scale, speed, and skill of the people building this is awesome.”
Stargate is the codename for OpenAI’s planned supercomputing facility, a massive project designed to support future generations of AI models. Estimated cost: Up to $100 billion, making it one of the most expensive tech infrastructure projects ever.
Just this week OpenAI's Stargate supercomputing project announced a global push: OpenAI for Countries. The initiative helps nations build local AI infrastructure, roll out custom ChatGPTs, and grow their own AI economies. It’s AI-as-diplomacy, and a direct counter to authoritarian tech exports. First stop: ten country partnerships and counting.
Microsoft [If You Can’t Beat the Protocol…]
Microsoft has adopted Google’s A2A protocol to power cross-platform AI agent collaboration in Azure AI Foundry and Copilot Studio. That’s right – Redmond is building its multi-agent future on Google’s open spec. In the agentic age, even tech giants are choosing interoperability over ego.
Speaking about Google, it’s sharing some pre Google I/O goodies:
Gemini now features implicit caching, offering up to 75% cost savings by automatically reusing prompt prefixes.
Meanwhile “Gemma just passed 150 million downloads and over 70k variants on Hugging Face”?
AWS’s new Generative AI Adoption Index shows where 2025 budgets are headed
Three things to say: 1. The Rise of the Chief AI Officer. 2. AI Talent is a Strategic Priority. 3. A Blended Build-vs-Buy Approach
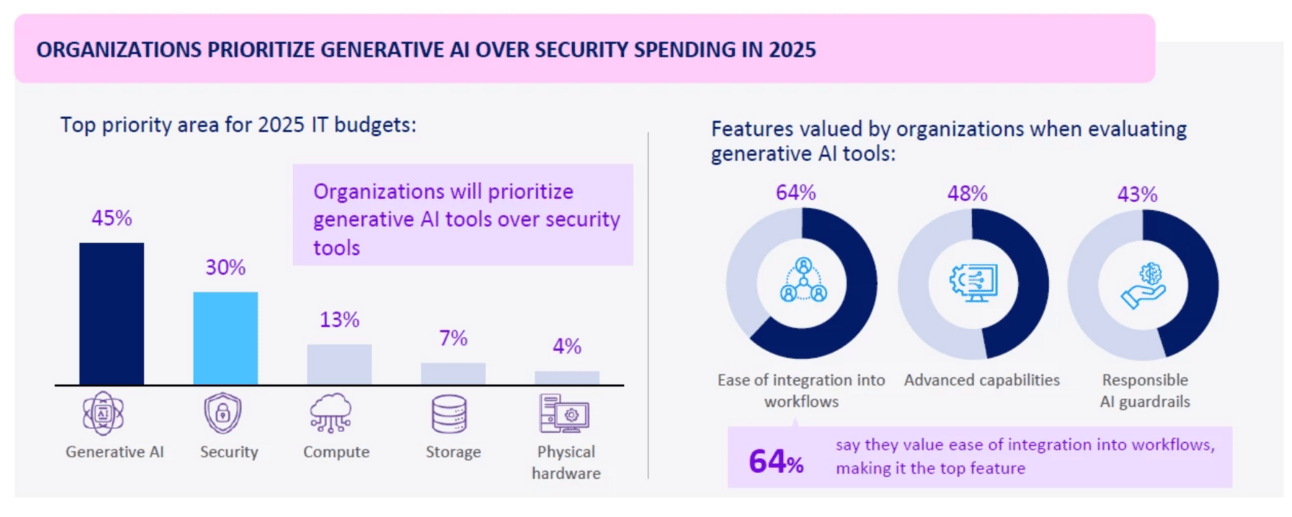
Image Credit: Amazon

Models to pay attention to:
Google introduces Gemini 2.5 Pro and Gemini Flash, two multimodal models that advance the frontier of video and agentic understanding. Gemini 2.5 Pro now processes 6-hour video inputs at low resolution with 2M-token context, achieving 84.7% on VideoMME—nearly matching full-res performance at lower compute cost → read the post
LTX-Video from Lightricks enables real-time, high-quality text-to-video and image-to-video generation using a diffusion-based pipeline with 30 FPS output; optimized for resolution and speed with quantized and distilled versions for different compute needs → read more
NVIDIA open-sourced Open Code Reasoning LLMs (7B, 14B, 32B) optimized for code reasoning tasks and backed by an OCR dataset; 30% more token-efficient and compatible with standard deployment frameworks → read more
Parakeet-TDT-0.6b-v2 from NVIDIA – is a robust 600M parameter speech model for English transcription. Supports long audios (up to 3 hours), with accurate punctuation, timestamps, and superior performance on spoken numbers and lyrics → try the model
Mistral Medium 3 balances SOTA performance with 8× lower cost and smooth enterprise deployment. Excels in coding and STEM tasks, outperforming LLaMA 4 Maverick and Cohere Command A at a fraction of the cost → read more
LLaMA-Omni 2 – is a real-time spoken chatbot based on Qwen2.5 (!), integrating a speech encoder and streaming speech decoder. Trained on just 200K speech dialogues, it beats models trained on millions of hours for spoken QA and instruction following → read more
Surveys
Multimodal Reasoning and Unified Architectures
🌟 Perception, Reason, Think, and Plan: A Survey on Large Multimodal Reasoning Models outlines the evolution of multimodal reasoning, from early modular systems to unified language-centric models capable of agentic behavior → read the paper

Image Credit: Perception, Reason, Think, and Plan
Unified Multimodal Understanding and Generation Models: Advances, Challenges, and Opportunities reviews efforts to unify multimodal understanding and generation, analyzing architectural trends and future directions for integration → read the paper

LLMs for Complex Reasoning and Problem Solving
Knowledge Augmented Complex Problem Solving with Large Language Models surveys techniques for using LLMs in complex real-world problem solving, covering multi-step reasoning, knowledge integration, and verification → read the paper
Sailing AI by the Stars: A Survey of Learning from Rewards in Post-Training and Test-Time Scaling of Large Language Models presents a unified view of reward-driven learning across post-training and inference stages, including RLHF, decoding strategies, and test-time correction → read the paper
The freshest research papers, categorized for your convenience
Going forward, we'll organize research papers by goal-oriented or functional categories to make it easier to explore related developments and compare approaches. As always, papers we particularly recommend are marked with 🌟
Improving Reasoning and Alignment in Language Models
[we will cover GPRO and Flow-GPRO in more detail on Wednesday] 🌟 Flow-GRPO: Training Flow Matching Models via Online RL combines flow matching and reinforcement learning for improved text-to-image generation, significantly boosting composition accuracy and human preference alignment → read the paper
🌟 Unified Multimodal Chain-of-Thought Reward Model through Reinforcement Fine-Tuning proposes a reward model that uses chain-of-thought reasoning across modalities, trained with reinforcement learning to improve reliability and robustness → read the paper
🌟 RM-R1: Reward Modeling as Reasoning introduces reward models that explicitly reason in natural language before scoring outputs, improving interpretability and alignment performance → read the paper
R1-Reward: Training Multimodal Reward Model Through Stable Reinforcement Learning applies a stable RL approach to train multimodal reward models that handle long-term reasoning better → read the paper
Putting the Value Back in RL: Better Test-Time Scaling by Unifying LLM Reasoners With Verifiers enhances test-time efficiency by unifying LLMs as both reasoners and verifiers, reintroducing value functions into RL → read the paper
Optimizing Chain-of-Thought Reasoners via Gradient Variance Minimization in Rejection Sampling and RL improves efficiency of reasoning model training by allocating inference compute dynamically per prompt → read the paper
🌟 Scalable Chain of Thoughts via Elastic Reasoning separates thinking and solution stages in reasoning models to better handle inference constraints → read the paper
🌟 X-Reasoner: Towards Generalizable Reasoning Across Modalities and Domains demonstrates that reasoning capabilities can transfer from text to multimodal and domain-specific tasks → read the paper
Chain-of-Thought Tokens are Computer Program Variables analyzes how intermediate reasoning steps behave like variables, offering insights into the mechanics of CoT → read the paper
Crosslingual Reasoning through Test-Time Scaling explores how English-trained reasoning models can generalize to other languages when test-time compute is scaled → read the paper
Enhancing Training Efficiency and Data Strategies
🌟 Practical Efficiency of Muon for Pretraining demonstrates that the Muon optimizer improves data and compute efficiency during large-scale training → read the paper (from Essential AI, a few founders of which are architects of Transformer architecture)
SIMPLEMIX: Frustratingly Simple Mixing of Off- and On-policy Data in Language Model Preference Learning shows that mixing on-policy and off-policy data improves alignment across open-ended and reasoning tasks → read the paper
🌟 Grokking in the Wild: Data Augmentation for Real-World Multi-Hop Reasoning with Transformers applies synthetic augmentation to knowledge graphs to enable grokking in real-world multi-hop reasoning tasks → read the paper
🌟 Teaching Models to Understand (but not Generate) High-risk Data introduces a selective loss function so that models can learn from high-risk content without replicating it → read the paper
Building Efficient and Deployable Architectures that Scale
RADLADS: Rapid Attention Distillation to Linear Attention Decoders at Scale presents a low-cost method for converting transformer models to efficient linear attention alternatives → read the paper
RetroInfer: A Vector-Storage Approach for Scalable Long-Context LLM Inference reimagines the key-value cache as a vector database for faster and memory-efficient long-context inference → read the paper
ReplaceMe: Network Simplification via Layer Pruning and Linear Transformations offers a training-free method to prune transformer layers while preserving performance with linear mappings → read the paper
🌟 LLM-Independent Adaptive RAG: Let the Question Speak for Itself proposes efficient, external-feature-driven methods to decide when retrieval is necessary in RAG pipelines → read the paper
Pangu Ultra MoE: How to Train Your Big MoE on Ascend NPUs details a recipe for training a 718B-parameter sparse MoE model on Ascend NPUs, optimizing for hardware efficiency and expert parallelism → read the paper
Benchmarking & Evaluation
On Path to Multimodal Generalist: General-Level and General-Bench introduces a benchmark and methodology to evaluate multimodal models’ progress toward generalist AI → read the paper
Benchmarking LLMs' Swarm Intelligence proposes SwarmBench to measure decentralized coordination capabilities of LLMs under swarm-like conditions → read the paper
AutoLibra: Agent Metric Induction from Open-Ended Feedback automatically generates evaluation metrics from natural language feedback to assess agent behavior → read the paper
G-FOCUS: Towards a Robust Method for Assessing UI Design Persuasiveness presents a benchmark and strategy for evaluating the persuasiveness of UI designs using vision-language models → read the paper
That’s all for today. Thank you for reading! Please send this newsletter to your colleagues if it can help them enhance their understanding of AI and stay ahead of the curve




